[AINews] $200 ChatGPT Pro and o1-full/pro, with vision, without API, and mixed reviews • ButtondownTwitterTwitter
Chapters
AI Twitter and Reddit Recap
AI Discord Recap Continued
Discussion on Various AI Discord Channels
LM Studio, GPU MODE, Torchtune, and More Discussions
Unsloth AI (Daniel Han) Research
Challenges and Discussions on Various Topics
LayerNorm in NeoX and OpenAI Announcements
Discussions on Language Models and AI Applications
GPU Mode Cool Links
Axolotl AI - Swag and Survey Incentives
Various AI Event Discussions
AI Twitter and Reddit Recap
AI Twitter Recap
- Claude Sonnet provided recaps on AI Twitter conversations for 12/4/2024 - 12/5/2024.
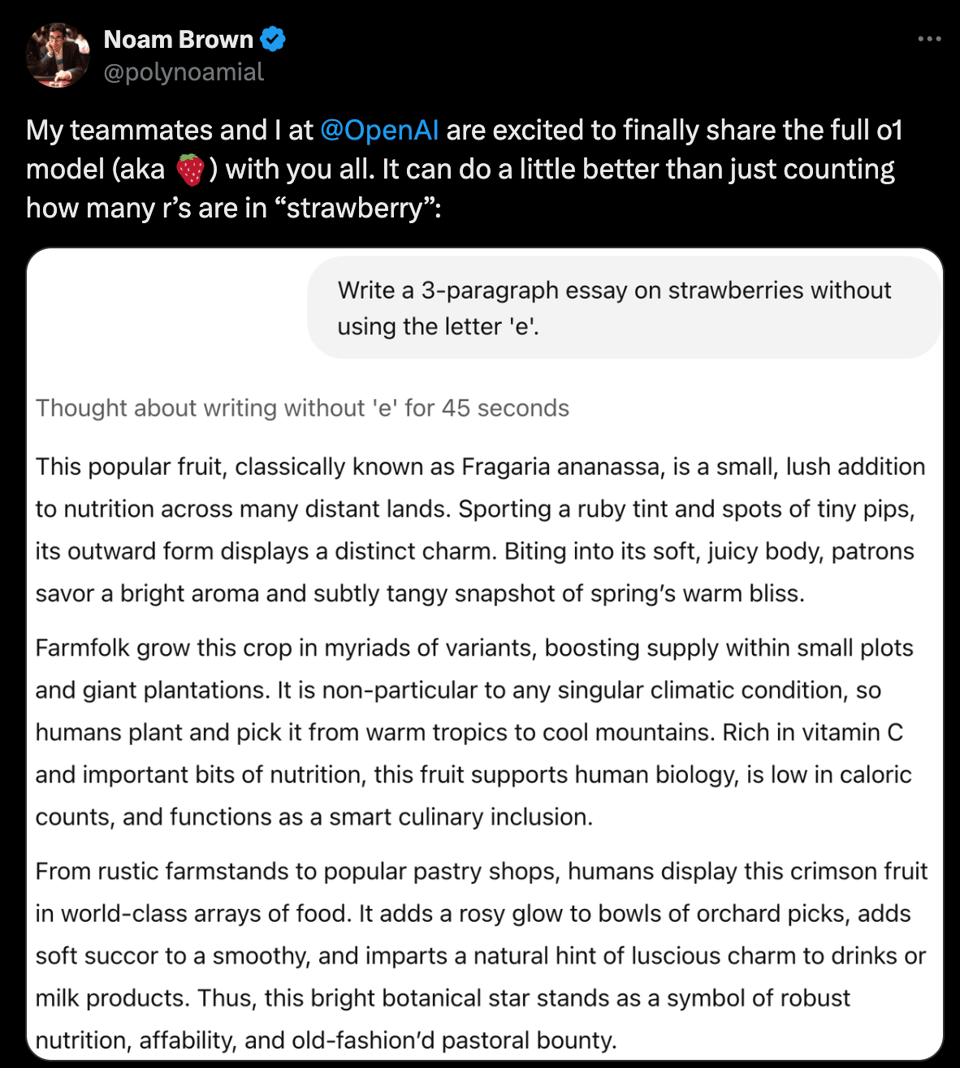
- OpenAI's o1 full/pro launch and reactions were noted, with mentions of the new $200 Pro tier.
- Google announced the release of PaliGemma 2 models for vision-language tasks.
- LlamaParse offered discounts for large document processing.
AI Reddit Recap for /r/LocalLlama
Theme 1: Google's PaliGemma 2
- Google unveiled new vision-language models called PaliGemma 2 in various sizes (3B, 10B, 28B). A Reddit user shared details about their capabilities and hardware requirements.
Theme 2: SAM 2 vs SAMURAI Performance
- A comparison post discussed the visual tracking models SAM 2 and SAMURAI, highlighting implementation limitations and challenges.
AI Discord Recap Continued
The Discord conversations continue with discussions on various AI topics and challenges faced by users in different platforms. These discussions cover issues such as resource exhaustion in Cursor IDE and Windsurf, the launch of new models like PaliGemma 2 and DeepThought-8B, as well as techniques like Dynamic 4-bit Quantization by Unsloth AI. Users also share experiences with fine-tuning models and comparing different IDEs for backend and UI development. The ongoing interest in the O1 model and its Pro Mode features remains a central theme in these conversations.
Discussion on Various AI Discord Channels
The Discord channels for different AI platforms feature a wide array of discussions and updates. Users are exploring improvements like group subscriptions for cost-effective access, resolving code generation failures, and managing token usage concerns with Firebase integration. New features like the mobile preview in Bolt and author pages in OpenRouter are met with enthusiasm, while challenges like error handling in Bolt and token-related enhancements in NotebookLM are being addressed. The AI community discusses model launches, optimizations, collaborations, and training efficiency across platforms like Nous Research AI and Cohere. Additionally, advancements in image generation, prompt crafting techniques, and drug discovery tools in Perplexity AI are highlighted.
LM Studio, GPU MODE, Torchtune, and More Discussions
This section covers various discussions from different Discord channels related to topics like LM Studio's REST API launch, Linux installation challenges, uninstalling LM Studio issues, GPU mode breakthroughs, Gemlite's performance boost, Triton usability challenges, weight pruning techniques, Federated learning advantages, Torchtune's checkpoint merging process, optimizing distributed checkpoint usage, reinvestigating LoRA weight merging, community GPU utilization, and more. The discussions include insights, challenges, and proposals related to AI technologies and advancements.
Unsloth AI (Daniel Han) Research
DeepThought-8B Offers New Reasoning Power: Introducing DeepThought-8B, a transparent reasoning model with JSON-structured thought chains and test-time compute scaling. It competes with 70B models and includes open weights with inference scripts.
Challenges in Llama 3.2 Vision Fine-Tuning: Users discuss fine-tuning Llama 3.2 Vision for recognition tasks with varying results, prompting consideration of using Florence-2 for a lighter and faster alternative.
Dynamic 4-bit Quantization Promoted: Insights shared on Dynamic 4-bit Quantization to compress models without accuracy loss, applied to models on Hugging Face, including Llama 3.2 Vision.
Sharing Insights on Quantization Methods: Requests for error analysis insights, code, or posts on the dynamic quantization method. Users keen to learn more for accuracy and performance comparison.
Exploring Options for Fine-Tuning: Discussions on switching from Llama 3.2 Vision to Florence-2 for fine-tuning based on performance variations, aiming to determine the most effective approach.
Challenges and Discussions on Various Topics
This section covers a range of topics discussed in different channels, including issues with database syncing, challenges with UI tweaks using Bolt, leveraging Firebase for game development, testing responsive designs, effective feature request management, concerns with Bolt's token usage, excitement over mobile preview release, GitHub repo integration, CORS issues with Firebase, error handling in Bolt, news from OpenRouter including token generation, Lambda model price reductions, author pages feature launch, Google AI Studio models outage, and Amazon Nova model family release. There are also discussions on C++ learning challenges, job acquisition in programming, Mojo language features, user-defined dialects, Eleuther's AI research, evaluation methods in LM Thunderdome, interpretability seminar by David Bau, and the GPT Neox development channel.
LayerNorm in NeoX and OpenAI Announcements
-
Mimicking OLMo's Non-parametric LayerNorm: A request to replicate the non-parametric LayerNorm from OLMo within a NeoX config.
-
Understanding LayerNorm Settings: Tips to achieve LayerNorm without adaptive gain and bias.
-
Layer Normalization Explained: Reference to the Layer Normalization paper explaining the operation and mathematical formulation.
-
Sam Altman discusses new product: Announcement of an upcoming event revealing an exciting new product development from OpenAI.
-
Stay updated during 12 Days of OpenAI: Encouragement for community participation in the 12 Days of OpenAI event to stay informed and engaged.
Discussions on Language Models and AI Applications
Cohere Discussion:
- Users explored Cohere themes, token prediction glitches, RAG implementation, Rerank 3.5 launch, and masked diffusion in LLMs.
- Feedback on the rerank 3.5 model integration and Cohere API issues were discussed.
- The community shared experiences with API integration, strict tools parameters, and performance comparisons between models.
Nous Research AI General:
- Discussions included model training efficiency, token speculation, optimizers, disruption in LLM performance, and continuous learning opportunities.
- Speculations on token rumors were entertained, and innovators explored optimizers and quantization.
Latent Space AI Chat:
- Updates featured OpenAI, ElevenLabs AI agents, Anduril OpenAI collaboration, PaliGemma 2 launch, and new AI models.
- OpenAI o1 enhancements, ElevenLabs AI agent launches, and Anduril's partnership with OpenAI were highlighted.
Stability.ai General Chat:
- Challenges in image generation, color control, testing new AI models, and community resources were discussed.
- Users explored color modification techniques, epoch understanding, and community tool recommendations.
Nous Research AI Recruitment:
- AI engineers were sought for multi-model integration projects.
- Multi-model integration opportunities and the potential for diverse AI applications were highlighted.
GPU Mode Cool Links
Dynamic 4-bit Quantization introduced:
- A blog post from Unsloth highlights Dynamic 4-bit Quantization, enabling a 20GB model to be reduced to 5GB while maintaining accuracy. The method claims to use <10% more VRAM than BitsandBytes' 4-bit and involves selectively choosing parameters to quantize.
HQQ-mix enhances 3-bit quantization:
- The HQQ-mix approach demonstrated that using a blend of 8-bit and 3-bit for specific rows can cut quantization error in half for Llama3 8B models. This method divides weight matrices into two sub-matrices and produces results through a combination of two matmuls.
Mixtral-8x7B model gets quantized:
- The new Mixtral-8x7B-Instruct model applies both 4-bit and 2-bit quantization, improving performance with a slight increase in size. This approach was inspired by discussions within the community, specifically by Artem Eliseev and Denis Mazur.
HQQ integration seeks efficiency:
- Members discussed incorporating HQQ into Unsloth, aiming for faster cuda kernel builds with options for skipping kernel compilation. They also explored the expansion to support various bit quantization, including 2, 3, 4, 5, 6, and 8-bit configurations.
Exploring GemLite kernels for quantization:
- Current support for GemLite kernels only exists for 1, 2, 4, and 8 bits, with future prototypes for 3-bit and 5-bit in development. There are suggestions on utilizing HQQ in TorchAO to avoid installing HQQ entirely.
Axolotl AI - Swag and Survey Incentives
New Axolotl swag is now available for distribution to all survey respondents who participated in the project. Contributors will receive merchandise as a token of appreciation, with an additional t-shirt included for those who completed the survey. Community members are encouraged to engage through the survey to receive exclusive merchandise. This initiative showcases the community's supportive and generous spirit in sharing resources and engaging with various projects within Axolotl AI.
Various AI Event Discussions
This section covers discussions from different AI events. It includes adapting prompts for DSPy, new user orientation, a live webinar on AI success, insights from JFrog's AI report, integrating MLOps and DevOps, data-mixing in LLMs, a decentralized pre-training competition, continuous benchmarking for improvement, and live metrics and leaderboards. Each event or topic presented provides valuable insights and updates within the AI community.
FAQ
Q: What is OpenAI's o1 full/pro launch?
A: OpenAI's o1 full/pro launch refers to the release of a new AI model with additional features and a Pro tier priced at $200.
Q: What are the key features of Google's PaliGemma 2 models?
A: Google's PaliGemma 2 models are designed for vision-language tasks and come in various sizes (3B, 10B, 28B).
Q: What is Dynamic 4-bit Quantization?
A: Dynamic 4-bit Quantization is a method to compress AI models without losing accuracy, with applications on platforms like Hugging Face.
Q: What is the significance of DeepThought-8B?
A: DeepThought-8B is a transparent reasoning model with JSON-structured thought chains and test-time compute scaling, competing with larger 70B models.
Q: What are some of the challenges discussed in Llama 3.2 Vision fine-tuning?
A: Users discuss fine-tuning Llama 3.2 Vision for recognition tasks with varying results, prompting consideration of using Florence-2 for a lighter and faster alternative.
Q: What is HQQ-mix and how does it relate to quantization?
A: HQQ-mix is an approach that combines 8-bit and 3-bit quantization for specific rows, effectively reducing quantization error in half for Llama3 8B models.
Get your own AI Agent Today
Thousands of businesses worldwide are using Chaindesk Generative
AI platform.
Don't get left behind - start building your
own custom AI chatbot now!