[AINews] Meta Llama 3.3: 405B/Nova Pro performance at 70B price • ButtondownTwitterTwitter
Chapters
AI Twitter and Reddit Recap
AI Discord Highlights
Unit Testing Techniques Using Cursor
Model Trends and Developments
Cursor IDE
Interconnects (Nathan Lambert) News
OpenAI API Discussions
Cohere Toolkit Communication
Nous Research AI
GPU Mode & LTX Video Model Implementation
Expired SSL Certificate Caused Downtime
AI Twitter and Reddit Recap
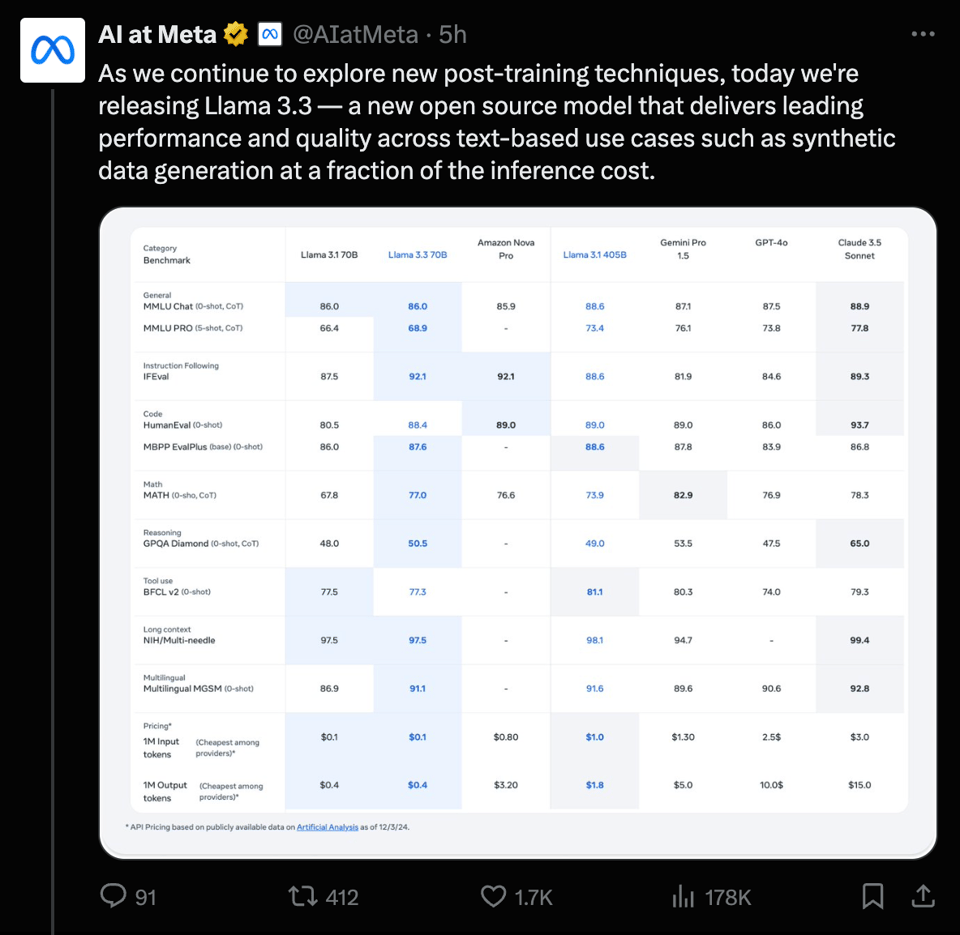
This section provides a recap of the key discussions and announcements from Twitter and Reddit related to AI. It covers updates on Meta's Llama 3.3 release, OpenAI's Reinforcement Fine-Tuning announcement, Google's Gemini performance updates, LlamaCloud and document processing features, as well as industry commentary on OpenAI's pricing. The Reddit recap includes discussions on Llama 3.3 70B performance, comparisons with other models like GPT-4o, Sonnet, and Gemini Pro, and the call for better models in the open-source community. The section highlights user reactions, performance metrics, and implications of these updates within the AI community.
AI Discord Highlights
The AI Discord channels are buzzing with discussions about various AI models, tools, and developments. In one channel, users express frustration over pricing changes and performance issues with tools like Windsurf and Claude, leading to a search for alternatives. Meanwhile, conversations in another channel focus on model releases such as Llama 3.3 and Gemini-exp-1206, highlighting their advanced features and competitive performance. Users also discuss the challenges of fine-tuning models due to VRAM limitations and eagerly anticipate upcoming releases like Unsloth Pro. Additionally, debates on maintaining performance and reliability continue regarding tools like Cursor IDE, with users sharing feedback on improvements and new features.
Unit Testing Techniques Using Cursor
Effective methods for writing unit tests with Cursor are explored, with a focus on shared techniques. Users are encouraged to share their experiences and methods for testing while awaiting a definitive response. This collaborative approach aims to enhance model discovery and analysis, promote cost-effective performance, introduce new models, and advance AI capabilities. The community also discusses fine-tuning models, model releases, GPU pricing, code interpreter constraints, and optimizing API usage.
Model Trends and Developments
This section covers various discussions on recent model developments and trends in the AI community:
- Comparison between 70B and 405B models, emphasizing cost-efficiency
- Introduction of Nous Distro for decentralized training, generating excitement among members
- Challenges faced in fine-tuning Mistral for kidney detection and community recommendations
- Leveraging LightGBM for improved tabular data performance and recommendations from members
- Optimizing data formatting for model training, including the use of Unsloth for classification
- Updates on the Popcorn Project with NVIDIA H100 benchmarks and its aims to enhance development experience
- Request for Triton's TMA support official release amid broken nightlies and concerns over nightly build stability
- Implementation of CUDA in LTX Video model leading to doubled GEMM speed on RTX 4090
- Exploration of quantization methods in TorchAO and dedication to optimizing model performance
- Discussion around the release of Llama 3.3 and community interest in its enhancements
Cursor IDE
Users have reported performance issues with Cursor IDE, experiencing connection failures and slow response times when using the Composer feature. Comparatively, Windsurf was noted to perform better in handling tasks smoothly, leading to a shift in user preferences. The latest updates to Cursor 0.43.6 integrated the Composer UI into the sidebar while removing functions like long context chat. Mixed user experiences were shared regarding the Composer feature failing to generate expected code or missing updates. Techniques for unit testing with Cursor were discussed with users seeking effective methods and shared experiences for testing.
Interconnects (Nathan Lambert) News
Gemini-exp-1206 outperforms rivals:
- The new Gemini-exp-1206 model has achieved first place overall and is tied with O1 on coding benchmarks, showcasing remarkable improvements over previous versions.
- OpenAI's demo revealed that fine-tuned O1-mini can outperform full O1 based on medical data, further highlighting Gemini's strong performance.
Llama 3.3 enhancements:
- Improvements in Llama 3.3 are attributed to new alignment processes and advancements in online reinforcement learning techniques.
- This model delivers performance comparable to the 405B model but is designed for cost-effective inference on standard developer workstations.
Launch of Qwen2-VL-72B:
- The Qwen2-VL-72B model has been released as part of Alibaba Cloud's new series, featuring state-of-the-art capabilities in visual understanding.
- This model can handle video understanding and operates across various devices, aiming to improve multimodal task performance.
Reinforcement Fine-Tuning discussions:
- The importance of fine-tuning using Reinforcement Learning (RL) was highlighted, with specific focus on its application in creating models that outperform existing counterparts.
- Notable mentions include the use of pre-defined graders for model training and recent discussions about the direction of RL training methodologies.
Upcoming slow period for AI work:
- Members expressed excitement about the upcoming holidays, indicating a potential slowdown in AI-related work and developments during this period.
- There are expectations for continued consistent output, with plans to ultimately produce more public content after the holidays.
OpenAI API Discussions
Self-Correcting Models: A Feasible Approach?
One member suggested using the model to self-correct its output, but another pointed out that achieving 100% accuracy isn't possible due to inference occurring in unaddressed memory.
- The need for an agentic framework was suggested for programmatic self-correction.
Consider non-LLM tools for OCR
A member advocated for using established non-LLM OCR libraries instead of relying on generative AI for consistent data extraction from PDFs.
- Concerns were raised about the risk of hallucination when using LLMs for extracting financial data.
The challenges of PDFs as a data source
Several members agreed that PDFs aren't a great API for data extraction due to their format limitations.
- Alternative suggestions included working upstream with report creators to establish better workflows.
Creating a spreadsheet for analysis
One member proposed to first use tools for pulling data into a spreadsheet, which could then be analyzed or visualized by ChatGPT.
- This process emphasizes structuring data before relying on LLMs for further analysis.
Cohere Toolkit Communication
The Coher Toolkit channel saw a new member introduce themselves, prompting a warm welcome from the community. This interaction highlights the supportive and engaging environment within the community, fostering a sense of belonging and camaraderie.
Nous Research AI
Nous Research AI ▷ #general (45 messages🔥):
-
Nous Distro explained as decentralized training: Users discussed Nous Distro involving decentralized training with reactions expressing excitement.
-
Llama 3.3 raises questions on base models: Conversation on Llama 3.3 questioned if a base model is used, with insights into emerging trends in model releases.
-
Safety concerns about misleading models: Concerns were raised about models intentionally misleading users, sparking skepticism among members.
-
User experiences with Llama 3.3: Users shared that Llama 3.3's math solutions are cleaner, more latex heavy, with mentions of framework implications on specific applications.
-
Performance metrics on comparison: Members discussed Sonnet model evaluations indicating varying performance scores, with reflections on real-world usability concerns.
GPU Mode & LTX Video Model Implementation
In this section, members discuss the implementation of the LTX Video model using CUDA technology, highlighting its 8bit GEMM speed improvements over cuBLAS FP8. The reimplementation includes features like FP8 Flash Attention 2, RMSNorm, RoPE Layer, and quantizers without sacrificing accuracy. Tests on the RTX 4090 showcased real-time generation speeds with just 60 denoising steps. Key features of the CUDA layers include Mixed Precision Fast Hadamard Transform and Mixed Precision FMA for improved speed and efficiency.
Expired SSL Certificate Caused Downtime
It was revealed that the site's downtime was due to an expired SSL certificate while hosted on Hetzner. Following the intervention, the site is confirmed to be back up and operational.
FAQ
Q: What are the key discussions and announcements related to AI from Twitter and Reddit?
A: The key discussions and announcements related to AI from Twitter and Reddit include updates on Meta's Llama 3.3 release, OpenAI's Reinforcement Fine-Tuning announcement, Google's Gemini performance updates, LlamaCloud and document processing features, and industry commentary on OpenAI's pricing. The Reddit recap covers discussions on Llama 3.3 performance, comparisons with models like GPT-4, Sonnet, and Gemini Pro, and the call for better models in the open-source community.
Q: What are the highlights of the AI Discord channel discussions?
A: The AI Discord channel discussions include frustration over pricing changes and performance issues with tools like Windsurf and Claude, discussions on model releases such as Llama 3.3 and Gemini-exp-1206, challenges of fine-tuning models, anticipation of upcoming releases like Unsloth Pro, debates on maintaining performance and reliability with tools like Cursor IDE, and techniques for writing unit tests with Cursor.
Q: What are some recent model developments and trends discussed in the AI community?
A: Some recent model developments and trends discussed in the AI community include comparisons between different model sizes for cost-efficiency, the introduction of Nous Distro for decentralized training, challenges in fine-tuning Mistral for kidney detection, leveraging LightGBM for tabular data performance, optimizing data formatting for model training, updates on the Popcorn Project, requests for Triton's TMA support release, implementation of CUDA in LTX Video model for doubled GEMM speed, exploration of quantization methods in TorchAO, and discussions around recent model releases like Llama 3.3.
Q: What are the key points regarding Gemini-exp-1206's performance compared to rivals?
A: Gemini-exp-1206 has achieved first place overall and tied with O1 on coding benchmarks, showing significant improvements over previous versions. OpenAI's demo revealed that fine-tuned O1-mini can outperform full O1 based on medical data, further emphasizing Gemini's strong performance.
Q: What are some of the enhancements in Llama 3.3?
A: The enhancements in Llama 3.3 are attributed to new alignment processes and advancements in online reinforcement learning techniques. This model delivers performance comparable to the 405B model but is specifically designed for cost-effective inference on standard developer workstations.
Q: What was the discussion surrounding Reinforcement Fine-Tuning?
A: The discussion highlighted the importance of fine-tuning using Reinforcement Learning (RL) and its application in creating models that outperform existing counterparts. Key aspects included the use of pre-defined graders for model training and recent discussions about the direction of RL training methodologies.
Q: What was mentioned about upcoming AI-related work during a slow period?
A: There was excitement expressed about the upcoming holidays possibly leading to a slowdown in AI-related work and developments during this period. However, there are expectations for continued consistent output, with plans to produce more public content after the holidays.
Q: What challenges were pointed out regarding using LLM for OCR?
A: There were concerns raised about using LLMs for OCR tasks due to the risk of hallucination. Members advocated for utilizing established non-LLM OCR libraries for consistent data extraction from PDFs.
Get your own AI Agent Today
Thousands of businesses worldwide are using Chaindesk Generative
AI platform.
Don't get left behind - start building your
own custom AI chatbot now!