[AINews] ModernBert: small new Retriever/Classifier workhorse, 8k context, 2T tokens, • ButtondownTwitterTwitter
Chapters
AI Model Releases and Performance
High-Level Discord Summaries
Recent Developments
Enhancing Model Performance and Functionality
Interconnects: Tax Implementation and Compliance
Interconnects and Discussions: Memes, AI, and OpenAI Updates
AI and Technology Discussions
AMD GPU Performance, Triton Optimization, cudaMemcpy, TMA Operations
LM Studio Discussion
More Updates and Discussions
Relevant Content
AI Model Releases and Performance
AI Model Releases and Performance
- DrJWrae announced the release of Gemini 2.0 Flash Thinking, built on their 2.0 Flash model for improved reasoning
- Lmarena_ai reported that Gemini-2.0-Flash-Thinking debuted as #1 across all categories in Chatbot Arena
- Bindureddy noted that the new O1 model scores 91.58 in Reasoning and is #1 on Livebench AI
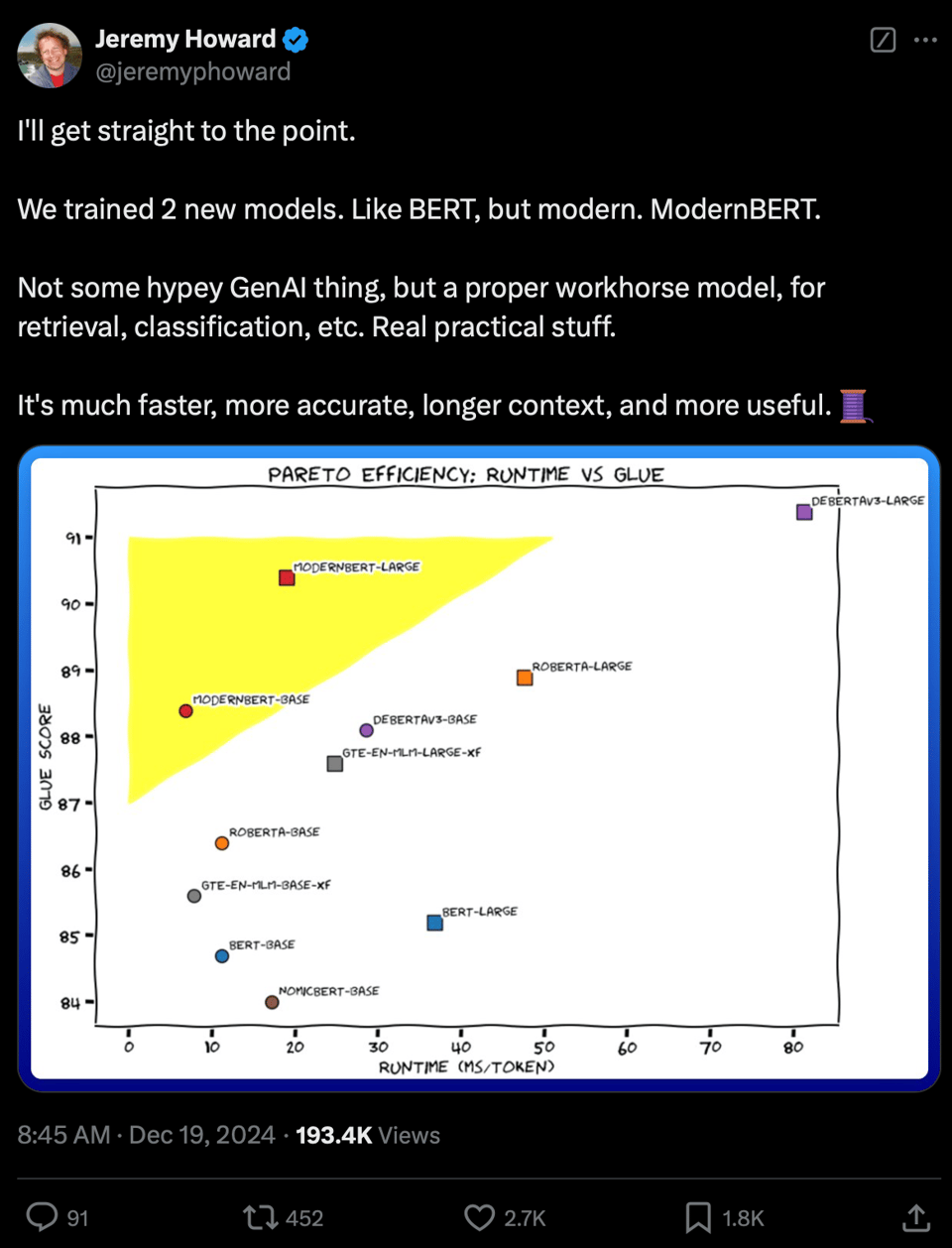
- Answerdotai and LightOnIO released ModernBERT with up to 8,192 tokens context length and improved performance
High-Level Discord Summaries
The discussions in various Discord channels highlighted advancements and debates in the AI field. Participants discussed topics such as the performance of AI models like Gemini 2.0 and Sonnet 3.5, the potential costs and benefits of different models, and the comparison of tools like Framer and DIY code. Multi-GPU support, quantization techniques, and the usage of Low Rank Adapters were also subjects of interest. The community shared insights on coding tools like Cursor IDE, interaction features in NotebookLM, and performance comparisons between Windsurf and Cursor. Overall, the Discord discussions shed light on the evolving landscape of AI technologies and tools.
Recent Developments
Eager contributors found it less stressful to refine reinforcement learning fundamentals, calling the process fun and beneficial. The recent days in the OpenAI community introduced enhancements in ChatGPT, XCode integration, a new experimental model by Google, YouTube clone demo with ChatGPT, and discussions on AI automation in software development. Eleuther members compared Fully Sharded Data Parallel to Tensor Parallelism, highlighted their concerns about high communication overhead, and discussed Natural Attention Optimizer. A debate on diffusion vs autoregressive models emerged, along with discussions on applying Koopman theory to neural networks and interpreting SAE-based OOD scores. Perplexity AI users discussed the referral program, concerns over You.com's responses, translation limits, and the Magic Spell Hypothesis. Aider Discord shared updates on Gemini, Aider and MCP integration, OpenAPI's operation, and GitHub Copilot Chat. Stackblitz users commended the Bolt & Supabase integration, shared frustrations with .env file resets, and discussed redundancy in code and public folder setup. Notebook LM Discord discussed interactive mode improvements, MySQL database hook, podcast recording tweaks, AI-generated space vlogs, and UI updates. Stability.ai discussed running SDXL on Ubuntu, ComfyUI issues, challenges in AI image perfection, quantum computing debates, and server problems on civitai.com. GPU MODE chat highlighted issues with RX 6750XT and VRChat, Triton testing on AMD GPUs, CARLA updates, MatX's hiring spree, and Alma's benchmark Python package. Latent Space discussions covered advances in AI agentic systems, Gemini 2.0, Databricks' funding, ModernBERT introduction, and Alec Radford's departure from OpenAI. OpenInterpreter chat touched on vision support, server mode execution queries, Google Gemini 2.0 features, and issues with installation and operability. LM Studio users addressed Safetensors errors, mobile app availability, AMD driver problems, image model integration, and hardware comparisons. OpenRouter community noted price cuts in LLM offerings, discussed crowdsourced AI stacks, DeepSeek for code learning, and proposals for programmatic API keys. Nous Research AI chat highlighted GitHub Copilot's free tier, praises for Granite 3.1-8B-Instruct, and discussions on improved model capabilities.
Enhancing Model Performance and Functionality
The section discusses various tools and techniques to improve model performance and functionality. It includes the introduction of models like Granite 3.1-8B-Instruct and LM Studio for efficient task handling. Additionally, debates on topics such as fine-tuning uniform instruction and generative physics using the Genesis engine are explored. Furthermore, the section delves into discussions on using negative indexing in Mojo, resolving bugs in SIMD-based keys, and tinkering with Mojo on Android. Lastly, it covers topics like synthetic data generation, rate-limiting debates, and features of different Python libraries in the AI space.
Interconnects: Tax Implementation and Compliance
Stripe Tax as a Safety Net: The importance of enabling Stripe Tax for digital services to simplify tax compliance, especially for Substack creators approaching revenue thresholds. This feature can avoid potential headaches with taxation authorities.### Confusion Around Substack's Tax Handling: Uncertainty about how Substack handles taxes and discussions about whether Substack is considered the marketplace operator responsible for tax collection. Nate pointed out complexities due to payments going directly to Substack's Stripe account.### Learning from Bigger Substackers: Noting that even larger Substackers lack knowledge about tax obligations, hinting at a trend among creators. This raised broader issues of accountability and responsibility in reporting earnings and taxes.### CPA and Tax Advice: Suggestions to consult a CPA for guidance on navigating tax requirements, particularly for digital service businesses. Interest in gathering more recommendations for proper compliance.### International Tax Challenges: Discussion on challenges of managing VAT in Europe and navigating tax liabilities in international contexts. Humorous note on consequences of failing to comply, highlighting the seriousness of these tax issues.
Interconnects and Discussions: Memes, AI, and OpenAI Updates
This section discusses various interactions and discussions related to AI integration and developments. It includes humorous references to AI in game shows, viral AI-related tweets, and community involvement in reviewing and correcting resources related to RLHF. Additionally, there are insights on OpenAI updates encouraging engagement with ChatGPT tools, as well as discussions on ChatGPT's integration with XCode, Google's experimental AI models, creating a YouTube clone using ChatGPT, the future of software engineering with AI, and AI performance benchmarks. The section also covers Eleuther discussions on topics like FSDP vs Tensor Parallelism, debunking EleutherAI token myths, natural attention optimizer, and challenges in model training debugging. Furthermore, in-depth conversations on ethical issues at Microsoft Research, applications of Koopman theory, diffusion vs autoregressive models, plagiarism concerns in ML research, and research submissions and oversight are explored. This section concludes with discussions on the independence of neural network activations, pre-image reconstruction methods, steered vs unsteered sparse autoencoders, and out-of-distribution evaluation.
AI and Technology Discussions
This section provides insights into various discussions and updates related to AI, technology, and research findings. It covers topics such as the Magic Spell Hypothesis, Tornado Alley exploration, advancements in AI models like Gemini 2.0, OpenAI access, model preferences for task automation, and testing various AI models for coding tasks. Additionally, it includes discussions on GitHub Copilot features, the integration of Bolt with Supabase, interactive modes for audio overviews, AI-generated video exploration, connecting MySQL database to NotebookLM, and AI utilization in storytelling. The content also delves into user experiences, challenges, and advancements in quantum computing, visual media quality produced by AI, website issues, and GPU-related debates on performance, choices, bottlenecking, VRAM needs, and concerns about next-gen GPUs.
AMD GPU Performance, Triton Optimization, cudaMemcpy, TMA Operations
This section discusses various topics related to GPU computing. It covers input shape requirements for tl.dot with AMD GPUs, performance optimization for Triton, faster alternatives to cudaMemcpy, behavior of tma_store_wait function in CUTLASS, and the need for documentation on TMA operations. Discussions include user queries on AMD GPU performance compared to PyTorch, removal of warp-specialization feature in Nvidia Hopper, and potential optimizations for memory transfers in CUDA programming. Overall, the section provides insights into optimizing GPU performance and exploring efficient computation methods.
LM Studio Discussion
This section consists of discussions within the LM Studio channel on Discord. Members share various issues and topics, including errors encountered while loading models, connecting to LM Studio from mobile devices, problems with AMD drivers, inquiries about image input models, and hardware configuration discussions. Users also exchange information on different LM Studio models, share hardware specifications, and provide solutions to issues faced within the LM Studio environment.
More Updates and Discussions
Continuing from the previous updates, users encountered issues with local storage for HuggingFace embedding models and Azure OpenAI rate limits. A clarification was provided on cache checking and rate limit solutions. Additionally, confusion over inserting TextNodes was addressed with advice on the correct method. In other discussions, Vision Parse was introduced as an open-source library for PDF to markdown conversion. Nomic.ai released the final part of the Data Mapping Series and discussed the importance of open-source contributions. The challenges faced in the installation of TinyChat were highlighted, and the need for a tiktoken replacement was acknowledged. Nomic BERT model issues were resolved, and new contributor roles were introduced in Torchtune discussions. Cohere API keys and rate limits were explained, and details about Cohere's platform were shared. Lastly, a hackathon submission deadline reminder was issued for LLM Agents.
Relevant Content
This section does not provide any specific content. It seems to be a placeholder or a section separator within the document.
FAQ
Q: What are some key advancements in AI models discussed in the essai?
A: Key advancements in AI models discussed include Gemini 2.0 Flash Thinking, O1 model, ModernBERT, Granite 3.1-8B-Instruct, ChatGPT, and more.
Q: What were some popular topics of discussion in the Discord channels regarding AI technologies and tools?
A: Popular topics of discussion included the performance of AI models like Gemini 2.0 and Sonnet 3.5, tools like Framer and DIY code, Multi-GPU support, quantization techniques, Low Rank Adapters, coding tools like Cursor IDE and NotebookLM, and performance comparisons between different tools.
Q: What were the notable debates or comparisons mentioned in the essai related to AI development?
A: Debates and comparisons mentioned include Fully Sharded Data Parallel vs Tensor Parallelism, diffusion vs autoregressive models, applying Koopman theory to neural networks, interpreting SAE-based OOD scores, and other discussions on various AI techniques and methodologies.
Q: What challenges or discussions were brought up regarding tax compliance and digital services like Substack?
A: Discussions included the importance of enabling Stripe Tax for digital services, confusion around Substack's tax handling and tax obligations for creators, suggestions to consult CPAs for tax advice, challenges of managing VAT in Europe, and international tax liabilities in digital service businesses.
Q: What insights were shared in the essai regarding GPU computing and performance optimization?
A: Insights included discussions on input shape requirements for tl.dot with AMD GPUs, performance optimization for Triton, memory transfer optimizations in CUDA programming, and overall exploration of efficient computation methods in GPU computing.
Q: What were some of the common issues and discussions within the LM Studio Discord channel?
A: Common issues discussed included errors loading models, connecting to LM Studio from mobile devices, problems with AMD drivers, inquiries about image input models, hardware configuration discussions, and sharing of information on LM Studio models and solutions to encountered issues.
Get your own AI Agent Today
Thousands of businesses worldwide are using Chaindesk Generative
AI platform.
Don't get left behind - start building your
own custom AI chatbot now!