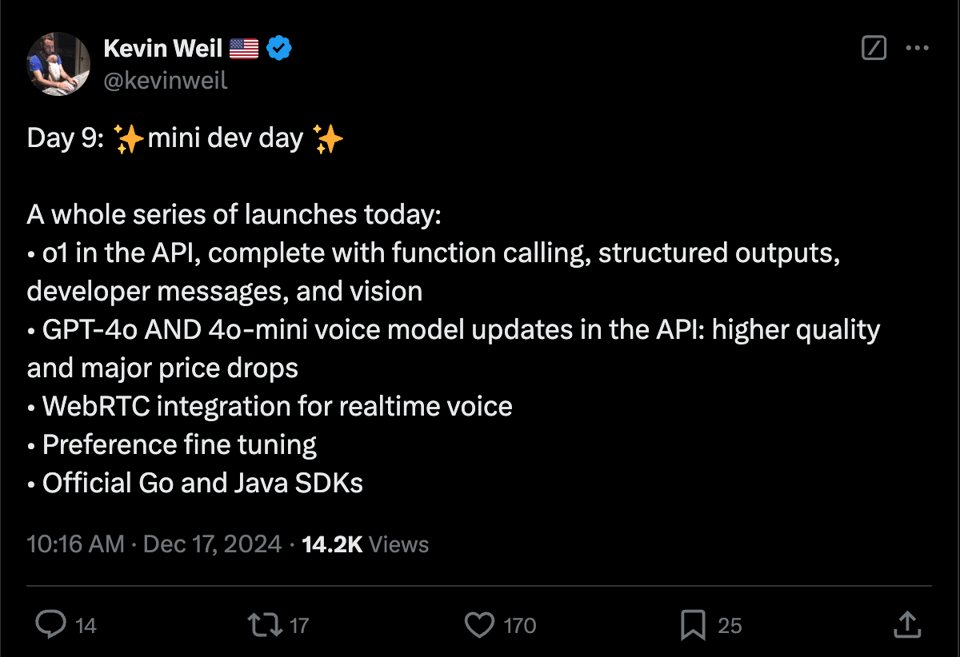
[AINews] o1 API, 4o/4o-mini in Realtime API + WebRTC, DPO Finetuning • ButtondownTwitterTwitter
Chapters
AI Reddit Recap
Discussion on AI Hardware Innovations
AI Integration and Functionality Updates
Optimizing PyTorch Docker Images, NVIDIA Jetson Nano, VLM Fine-tuning, Chain of Thought Dataset Generation
User Experiences and Discussions on AI Tools
Community Engagement and Problem-Solving
Token Management, Project Sharing, and Debugging Advice
OpenRouter and Structured Outputs
GPU Performance and Hardware Updates
LlamaIndex Blog and Agentic AI SDR
Berkeley Function Calling Discussion
AI Reddit Recap
/r/LocalLlama Recap:
Theme 1. Falcon 3 Emerges with Impressive Token Training and Diversified Models
-
Falcon 3 just dropped: Falcon 3 has been released, showcasing impressive benchmarks according to a Hugging Face blog post. The release highlights significant advancements in AI model performance.
- Model Performance and Benchmarks: The Falcon 3 release includes models ranging from 1B to 10B, trained on 14 trillion tokens. The 10B-Base model is noted for being state-of-the-art in its category, with specific performance scores such as 24.77 on MATH-Lvl5 and 83.0 on GSM8K. The benchmarks indicate that Falcon 3 is competitive with other models like Qwen 2.5 14B and Llama-3.1-8B.
- Licensing Concerns and Bitnet Model: There are concerns about the model's license, which includes a "rug pull clause" that could limit its use geographically. The release of a BitNet model is discussed, with some noting the model's poor benchmark performance compared to traditional FP16 models, although it allows for more parameters on the same hardware.
Discussion on AI Hardware Innovations
The section presents various discussions on AI hardware innovations and advancements. It covers topics such as the introductions of new hardware like Jetson Orin Nano, the release of ZOTAC GeForce RTX 5090 with 32GB GDDR7 memory, and Falcon 3 Family. Discussions delve into the features, capabilities, and potential impacts of these new hardware offerings in AI applications. Comparisons with existing hardware like Raspberry Pi and Apple's M1/M4 Mac mini are made, highlighting the advantages and limitations of each. Additionally, concerns about memory bandwidth, performance, and specialized use cases versus general-purpose computing needs are discussed within the context of these new hardware releases.
AI Integration and Functionality Updates
This section delves into various advancements and discussions in the AI community. It covers topics such as integrating AI into IT call centers with humorous scenarios, expanding multi-language support in NotebookLM, and performance comparisons in different AI models. Discussions include the optimization of AI models, enhancements in API key management, strategies for image retrieval using embeddings, and seeking sponsors for hackathons. Additionally, it explores issues with Bolt integration, challenges faced with AI accents and realism, updates on DevDay events, and adaptations in pricing models. The section also touches on the evolution of GPU hardware, diverse AI APIs, and new features introduced by different AI platforms.
Optimizing PyTorch Docker Images, NVIDIA Jetson Nano, VLM Fine-tuning, Chain of Thought Dataset Generation
- Optimizing PyTorch Docker Images: Official PyTorch Docker images are large, ranging from 3-7 GB, but can be reduced in size using a 30MB Ubuntu base image and Conda for managing CUDA libraries.
- NVIDIA Jetson Nano Super Launch: NVIDIA introduced the Jetson Nano Super, a compact AI computer offering 70-T operations per second for robotics applications, priced at $249 and supporting advanced models like LLMs. Users discussed enhancing Jetson Orin performance with JetPack 6.1 and deploying LLM inference on devices like AGX Orin and Raspberry Pi 5.
- VLM Fine-tuning with Axolotl and TRL: Resources for VLM fine-tuning using Axolotl, Unslosh, and Hugging Face TRL were shared, noting the process is resource-intensive and requires significant computational power.
- Chain of Thought Dataset Generation: A project was initiated to evaluate which CoT forms enhance model performance, utilizing reinforcement learning for optimization and showing initial progress with 119 riddles solved.
User Experiences and Discussions on AI Tools
Understanding Codeium's pricing and credits:
- Users questioned the ability to purchase larger blocks of Flex credits
- Conversations focused on newly established credit limits and plans
Varied experiences using AI code generation:
- Users noted mixed results with Codeium, mentioning issues with AI making changes that broke expected functionality
- Discussion included an example of AI altering unit tests without understanding intended functionality
Codeium plugin display font size problems:
- Concerns raised about small font size of the Codeium chatbot within JetBrains IDEs
- Troubleshooting steps discussed for inconsistent display
Recommendations for code review tools:
- Suggestion made for Code Rabbit AI as an alternative tool for code reviews
- Conversation sparked about evolving landscape of code review tools and user preferences within paid options
Links Mentioned:
- Tweet from NVIDIA AI Developer (@NVIDIAAIDev)
- Hello There GIF - Hello there - Discover & Share GIFs
- Plans and Pricing Updates
- Add Gemini 2.0 | Feature Requests | Codeium
- GitHub - SchneiderSam/awesome-windsurfrules
Link mentioned:
Community Engagement and Problem-Solving
This section delves into various discussions within different Discord channels where members share experiences, seek assistance, and engage with new features. From exploring interactive mode engagement to challenges with interactive mode features and feedback on new UI layouts, users actively participate in enhancing their user experience. Insights on game strategy guide utilization, exporting notes for improved functionality, and the beta interactive mode usage reflect a community eager to enhance interactions with AI systems. Additionally, discussions on Python version compatibility, model performance, and multi-GPU training highlight ongoing efforts to optimize training processes and address technical concerns. The section also touches upon innovative AI models, financial speculations, and continual pre-training strategies, showcasing a diverse range of topics and interests within the community.
Token Management, Project Sharing, and Debugging Advice
Concerns were raised about the effective management of tokens, with users expressing frustration over unexpected consumption. Users were reminded of monthly token limits and advised to be mindful of replacement costs. Additionally, users inquired about sharing websites built using Bolt, emphasizing the collaborative nature within the community. Interest in sharing completed projects indicated a strong sense of community cooperation. Lastly, advice on debugging and utilizing online resources for better coding practices was shared, highlighting the importance of seeking external help and resources for improving coding skills.
OpenRouter and Structured Outputs
- LLM Outputs to JSON Schema: The platform makes it easier to constrain LLM outputs to a JSON schema, streamlining development processes. Visit the demo here.
- Normalization of Structured Outputs: The platform now normalizes structured outputs across 8 different model companies and includes 8 free models. This broad support aims to facilitate smoother integration of various models into applications, emphasizing the underrated nature of structured outputs.
GPU Performance and Hardware Updates
- Despite GPU configurations, issues of random GPU utilization at 25% may require adjustment.
- Concerns about verifying Llama model settings to ensure CUDA is enabled for effective GPU usage.
- Zotac's accidental listing of upcoming RTX 50 GPUs with advanced specs like RTX 5090 featuring 32GB GDDR7 memory.
- Users facing problems with AMD GPU drivers like 24.12.1, finding performance boosts by reverting to 24.10.1.
- Discussions in the Stability.ai channel about Stable Diffusion courses, choosing hardware for AI tasks, bot detection methods, creating Lora models, and using the latest AI models.
- In the GPU MODE section, discussions on CUDA Graph and cudaMemcpyAsync, compute throughput on 4090, issues with cudaMemcpyAsync in CUDA Graph mode, and seeking examples for CUDA Graph issues.
- Updates in Modular (Mojo) channel regarding Mojo v24.6 release, Python importing Mojo kernels, GPU support, kernel programming APIs, and revisions in Mojo documentation.
LlamaIndex Blog and Agentic AI SDR
The LlamaIndex blog section highlights the launch of LlamaReport for converting document databases into human-readable reports, Agentic AI SDR for lead generation, and Composio platform for creating intelligent agents. Each tool offers unique capabilities to enhance productivity and streamline tasks. With LlamaReport making documents readable, Agentic AI SDR generating leads, and Composio empowering intelligent agents, users can explore innovative solutions for various tasks.
Berkeley Function Calling Discussion
The Gorilla LLM (Berkeley Function Calling) section discusses inquiries and overviews related to the BFCL Leaderboard V3. Members inquire about the function call demo's operational status and loading issues. The discussion covers evaluation criteria, expanded datasets, and methodologies for accurate function calls in various versions of the Berkeley Function Calling Leaderboard.
FAQ
Q: What is Falcon 3 and what are some key features mentioned in the essai?
A: Falcon 3 is a newly released AI model that includes models ranging from 1B to 10B, trained on 14 trillion tokens. The 10B-Base model is state-of-the-art and competitive with models like Qwen 2.5 14B and Llama-3.1-8B.
Q: What are the concerns raised about Falcon 3's licensing and the Bitnet model?
A: There are concerns about Falcon 3's license, including a 'rug pull clause' that could restrict its geographical usage. The BitNet model has poor benchmark performance compared to traditional models but allows for more parameters on the same hardware.
Q: What were the key hardware innovations and advancements discussed in the essai?
A: The essai discussed new hardware like Jetson Orin Nano, ZOTAC GeForce RTX 5090 with 32GB GDDR7 memory, and the Falcon 3 Family. Comparisons with existing hardware like Raspberry Pi and Apple's M1/M4 Mac mini were made to highlight advantages and limitations.
Q: What were some of the topics covered in the AI community discussions within the essai?
A: The discussions included integrating AI into IT call centers, expanding multi-language support in NotebookLM, optimizing AI models, API key management, strategies for image retrieval using embeddings, Bolt integration issues, challenges with AI accents, updates on DevDay events, and adaptations in pricing models.
Q: How can the official PyTorch Docker images be optimized in terms of size?
A: The official PyTorch Docker images, which are large ranging from 3-7 GB, can be optimized by using a 30MB Ubuntu base image and Conda for managing CUDA libraries.
Q: What was discussed regarding the NVIDIA Jetson Nano Super launch and its applications?
A: NVIDIA introduced the Jetson Nano Super, a compact AI computer offering 70-T operations per second for robotics applications, priced at $249. Users discussed enhancing Jetson Orin performance with JetPack 6.1 and deploying LLM inference on devices like AGX Orin and Raspberry Pi 5.
Q: What were some resources mentioned for VLM fine-tuning and the challenges associated with it?
A: Resources for VLM fine-tuning using Axolotl, Unslosh, and Hugging Face TRL were shared, noting the resource-intensive process that requires significant computational power.
Get your own AI Agent Today
Thousands of businesses worldwide are using Chaindesk Generative
AI platform.
Don't get left behind - start building your
own custom AI chatbot now!