[AINews] o3 solves AIME, GPQA, Codeforces, makes 11 years of progress in ARC-AGI and 25% in FrontierMath • ButtondownTwitterTwitter
Chapters
AI Twitter Recap
Deliberative Alignment Training Approach and AI Advancements
AI Editor Madness: Codeium, Cursor, Aider, and More
Modular Mojo Discord
AI Discord Discussions
Interconnects ML Drama
Interconnects (Nathan Lambert) - Random Conversations
Installation Challenges, Kaggle Access, JSON Formatting, Llama Models, and Research AI Discussions
Properties and Features of Modular (Mojo 🔥)
OpenAI Announces New Models and Departures
Cohere Discussion
Problematic Situations and Solutions in GPU Processing
Various Discussions on Different Topics
AI Twitter Recap
AI Twitter Recap
All recaps done by Claude 3.5 Sonnet, best of 4 runs.
OpenAI Model Releases (o3 and o3-mini)
-
o3 and o3-mini Announcements and Performance: @polynoamial announced o3 and o3-mini, highlighting o3 achieving 75.7% on ARC-AGI and 87.5% with high compute. @sama expressed excitement for the release and emphasized the safety testing underway.
-
Benchmark Achievements of o3: @dmdohan noted o3 scoring 75.7% on ARC-AGI and @goodside congratulated the team for o3 achieving new SOTA on ARC-AGI.
Other AI Model Releases (Qwen2.5, Google Gemini, Anthropic Claude)
-
Qwen2.5 Technical Advancements: @huybery released the Qwen2.5 Technical Report, detailing improvements in data quality, synthetic data pipelines, and reinforcement learning methods enhancing math and coding capabilities.
-
Google Gemini Flash Thinking: @shane_guML discussed Gemini Flash 2.0 Thinking, describing it as fast, great, and cheap, outperforming competitors in reasoning tasks.
-
Anthropic Claude Updates: @AnthropicAI shared insights into Anthropic's work on AI safety and scaling, emphasizing their responsible scaling policy and future directions.
Benchmarking and Performance Metrics
-
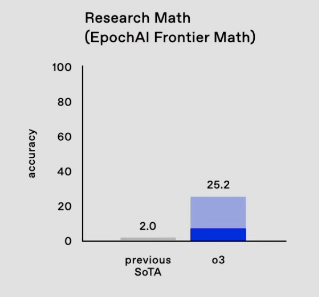
FrontierMath and ARC-AGI Scores: @dmdohan highlighted o3's 25% on FrontierMath, a significant improvement from the previous 2%. Additionally, @cwolferesearch showcased o3's performance on multiple benchmarks, including SWE-bench and GPQA.
-
Evaluation Methods and Challenges: @fchollet discussed the limitations of scaling laws and the importance of downstream task performance over traditional test loss metrics.
AI Safety, Alignment, and Ethics
- Deliberative Alignment for Safer Models: @cwolferesearch
Deliberative Alignment Training Approach and AI Advancements
Introduced Deliberative Alignment, a training approach aimed at enhancing model safety through chain-of-thought reasoning to adhere to safety specifications. Chamath emphasized considering societal implications of AI advancements and their impact on future generations. Various AI tools and applications were introduced, including CodeLLM for enhanced coding, LlamaParse for audio file processing, and Stream-K for improved kernel implementations. Memes and humor related to AI and culture were shared on Twitter. Additionally, AI research and technical insights were shared, such as MoE inference costs, neural video watermarking framework, and a survey on LLM inference-time self-improvement.
AI Editor Madness: Codeium, Cursor, Aider, and More
OpenAI skipped “O2” over rumored trademark conflicts and rolled out O3 just months after O1. The breakneck progression from one frontier model to the next amazed developers. Cursor 0.44.5 was praised for its productivity boost, leading users to return from rival IDEs with a fresh $100M funding round adding hype. Codeium’s Windsurf update enabled bug reports to be sent directly to Cascade, streamlining debugging. Aider and Cline collaborated to handle code tweaks and automation tasks efficiently. Theme 3 delved into debates on LoRA's effectiveness, merging QAT with LoRA for leaner LLMs, and the challenges of vocab pruning. In Theme 4, discussions revolved around agents, RL methods, and rival model showdowns like HL Chat, RL without full verification, and Gemini 2.0 Flash Thinking. Theme 5 highlighted creative and multimedia AI tools like Notebook LM for podcast automation, SDXL combining with LoRA for anime scenes, and AniDoc transforming sketches into colored animations.
Modular Mojo Discord
- FFI Friction: v24.6 Tangle: Developers encountered clashes with the standard library's built-in write function when upgrading from v24.5 to v24.6 in Mojo, suggesting a workaround using FileDescriptor.
- Libc Bindings for Leaner Mojo: Members advocated for broader libc bindings for better integration with Mojo and proposed consolidating these bindings into a single repository.
- Float Parsing Hits a Snag: Porting float parsing from Lemire fell short, prompting a pending PR to upgrade atof and enhance numeric handling for improved performance.
- Tensorlike Trait Tussle: Discussions at GitHub Issue #274 highlighted requests for tensor.Tensor to implement tensor_utils.TensorLike, sparking debates on the trait vs. type distinction.
- Modular Mail: Wrapping Up 2024: Modular expressed gratitude for the community's contributions in 2024 and announced a holiday shutdown until January 6, encouraging feedback on the 24.6 release for an exciting 2025 ahead.
AI Discord Discussions
- Litellm Proxy Gains Traction: Participants discuss using Litellm as a self-hosted or managed service, emphasizing its integration benefits.
- Synthetic Data Sparks LLM Upgrades: Dialogue covers the impact of synthetic data on smaller models, noting mixed results but optimistic push for reasoning studies.
- Optimization Costs Stir Concerns: Conversations highlight concerns over escalating optimizer costs, suggesting strategies like capping calls or parameters to avoid overspending.
- MIPRO 'Light' Mode Tames Resources: Early adopters mention the efficiency of running optimization steps with fewer resources, hinting at promising outcomes for trials.
- KTO and Liger: A Surprising Combo: Guild members discuss the integration of Liger with KTO, focusing on boosting model performance and addressing loss parity concerns. Continuing scrutiny on training metrics is expected.
- DPO Dreams: Liger Eyes Next Steps: A team prioritizes Liger DPO for stable operations, despite facing challenges related to loss parity struggles.
Interconnects ML Drama
François Chollet's statements, O1 model characteristics, Subbarao/Miles Brundage incident, AI community reactions, Recent incidents involving GDM director
-
Chollet compares O1 to AlphaGo: François Chollet stated that O1 operates similarly to AlphaGo, suggesting both use extensive processes for single outputs, likening the two in analogy.
- He emphasized that calling O1 purely an LLM is misleading, much like mislabeling AlphaGo as merely a convnet.
-
Discussions on O1's search functionalities: Members expressed confusion over whether O1 performs any explicit search, with some insisting that existing knowledge should clarify this aspect.
- Some speculate that the model’s performance could be replicated through search mechanisms, prompting debates on its underlying mechanisms.
-
Subbarao/Miles Brundage incident revisited: There was a mention of an incident involving Subbarao and Miles Brundage that questioned the scientific basis of how models like O1 operate, affirming it's just a language model.
- This incident highlights ongoing challenges in understanding and defining the capabilities and nature of advanced AI models.
Interconnects (Nathan Lambert) - Random Conversations
Community Exchanges
- Members reacted to an incident involving GDM director David Budden, expressing disappointment over bad behavior within the community.
- Some conversations highlighted the negative impact on the community's overall perception.
Legal Pressures
- A tweet deletion raised concerns about potential legal implications.
- Surprise and concern were expressed over the seriousness of the content involved.
Discord Interactions
- Humorous exchanges about Discord stalking and excitement over 'o3'.
- Members boasted about timing rivalry and competition in discussions.
OpenAI Model Discussions
- Discussions on OpenAI's 'O3' model naming, meme culture challenges, model names speculation, and claims of diminishing returns in GPT models.
- Humorous tweets referenced OpenAI's model developments.
Reinforcement Learning Discussions
- Members raised concerns about verifiability in RL outputs and noisy reward models.
- Enthusiasm for future research in Large Language Models (LLM) and RL was expressed.
Installation Challenges, Kaggle Access, JSON Formatting, Llama Models, and Research AI Discussions
This section discusses various topics related to installation challenges on Windows, accessing GPU via Kaggle, JSON formatting issues, utilizing Llama models, and insights from Nous Research AI discussions regarding O3 model performance, development of agentic systems, job market concerns with AI advancements, evaluating ARC-AGI benchmark success, and regulatory perspectives on AI assets. Links to relevant resources are also mentioned for further exploration.
Properties and Features of Modular (Mojo 🔥)
This section discusses various functional aspects of Modular (Mojo 🔥): The debate around using properties for efficient code and unexpected behaviors, the need for accurate naming conventions in benchmark directories, and the development of libc bindings for Mojo's functionality. Additionally, the performance of float parsing and the implementation of the TensorLike trait in Tensor are explored, with suggestions for improved usability and streamlined processes. The community expresses gratitude for the collaborative efforts in shaping Modular's journey and anticipates a promising future post-holiday break.
OpenAI Announces New Models and Departures
The section discusses OpenAI's latest developments, including the introduction of the o3 reasoning model achieving significant performance improvements, Alec Radford's departure causing speculation about OpenAI's future direction, economic implications of AI models' performance, safety testing for AI models, and insights into new AI evaluation methods. The discussion also highlights OpenAI's call for safety testing volunteers, with links to relevant tweets and announcements.
Cohere Discussion
Excitement for MLX and new models:
Community members expressed enthusiasm for new MLX support regarding Cohere's c4ai-command-r7b model and shared installation tips. One member noted that getting models like VLLM integrated early would help streamline contributions within the open-source community.
Cohere's capabilities showcased:
A community review highlighted Cohere's model performing well on a 211009 token danganronpa fanfic, showcasing impressive memory efficiency using 11.5 GB. This sparked discussions around its architecture, particularly its 128K context length and lack of positional encoding, which may enhance generalization.
Collaboration on updates with Cohere:
Members discussed ways to involve Cohere more directly in supporting new releases early, noting the success of similar collaborations with Mistral. Contributors believe that this could lead to a smoother integration process for models and updates like VLLM.
GPTJ enhancements noted:
There was speculation on the impact of GPT-J's rope mechanism on the accuracy of attention, suggesting that it may be more effective than previous configurations. Members reflected on past implementations of 4096 sliding windows, reiterating their belief in advancements brought by the newer architecture.
Updates and release anticipation:
Members noted upcoming releases, particularly around the O3 model's expected capabilities, hinting at innovative features akin to GPT-4. These discussions highlighted community excitement about potential functionalities, including voice interactions with models similar to those used for festive applications.
Problematic Situations and Solutions in GPU Processing
Issue 1: Potential Race Condition in Memory Operations
A user raised concerns about a possible race condition related to how memory is recorded in the graph, indicating a need for debugging due to complex interactions.
- Uncertainty around the function of AsyncMemCpyD2D in TensorRT context was also discussed by another user.
Explanation of Implicit Memory Fencing
A member clarified the concept of implicit memory fencing after kernel execution, highlighting that memory will be automatically fenced to ensure data integrity.
- A feedback acknowledging the explanation was shared.
Confusion with cute::composite Function
A user expressed confusion about utilizing cute::composite function to compose the global layout with smemLayoutX for grid partitioning, recognizing its significance despite the confusion.
- Dialogue expressed mutual puzzlement about the function's complexity and importance.
Various Discussions on Different Topics
ter</code> Curiosity about OpenInterpreter's server mode; Feedback on Google Gemini 2.0's capabilities; Praise for Local LLM Integration; Using SSH with OpenInterpreter; Concerns over Referral Spam. #### General Discussions on Axolotl AI: Liger integrates KTO; Working on Liger DPO; Community concerns over issues. #### Discussion on Gorilla LLM: Introduction of new Watt-tool models; Support requested for PR review. #### Other Announcements: Chenyuy to handle inactive PRs; Link to GitHub PR for new models.
FAQ
Q: What is the significance of the OpenAI model releases o3 and o3-mini?
A: The OpenAI model releases o3 and o3-mini achieved high benchmark scores on ARC-AGI, showcasing improved performance and prompting excitement in the AI community.
Q: What are some technical advancements highlighted in the Qwen2.5 Technical Report?
A: The Qwen2.5 Technical Report detailed improvements in data quality, synthetic data pipelines, reinforcement learning methods, and enhanced math and coding capabilities.
Q: What updates were shared regarding Anthropic Claude's work on AI safety and scaling?
A: Anthropic Claude shared insights into their work on AI safety and scaling, emphasizing their responsible scaling policy and future directions in ensuring safe AI development.
Q: What challenges were discussed in terms of evaluation methods and performance metrics in AI models?
A: Discussions highlighted challenges such as limitations of scaling laws, the importance of downstream task performance over traditional test loss metrics, and the need for continuous improvement in evaluation methods.
Q: What are some key points from the discussions on AI safety, alignment, and ethics?
A: Discussions involved introducing Deliberative Alignment for safer models, emphasizing societal implications of AI advancements, introducing various AI tools and applications, and sharing AI research insights on technical advancements.
Q: What comparisons were made between the O1 model and AlphaGo by François Chollet?
A: François Chollet highlighted similarities between O1 and AlphaGo in terms of extensive processes for single outputs, noting that labeling O1 purely as an LLM is misleading, similar to mislabeling AlphaGo as merely a convolutional neural network.
Q: What incident involving Subbarao and Miles Brundage raised questions about the scientific basis of advanced AI models like O1?
A: The incident involving Subbarao and Miles Brundage questioned the scientific basis of how models like O1 operate, affirming that O1 is more than just a language model, highlighting ongoing challenges in understanding and defining the capabilities of advanced AI models.
Q: What were some community exchanges related to the AI Twitter Recap?
A: Community exchanges included reactions to incidents involving GDM director David Budden, expressions of disappointment over negative behavior within the community, and discussions on legal pressures and Discord interactions.
Get your own AI Agent Today
Thousands of businesses worldwide are using Chaindesk Generative
AI platform.
Don't get left behind - start building your
own custom AI chatbot now!