[AINews] Pixtral Large (124B) beats Llama 3.2 90B with updated Mistral Large 24.11 • ButtondownTwitterTwitter
Chapters
AI Reddit Recap: /r/LocalLlama Recap
Qwen 2.5 Coder 32B vs Claude 3.5 Sonnet: Performance and Comparison
Discord Discussions on Innovative AI Technologies
Structured Citations and Perplexity Models
Off-Topic Discussions
Perplexity AI Announcements and Messages
HuggingFace: Questions and Tips
Exploring Prompt Engineering and AI Discussions
Understanding the Advancements in LM Studio and GPU Usage
Interconnects - AI General Chat
GPU Mode - Triton Puzzles
Mojo Benchmarking and Issues
Cohere Developer Office Hours and Toolkits
Updates and Improvements in Various Areas
Messaging Interaction
AI Reddit Recap: /r/LocalLlama Recap
This section discusses a recap of discussions on the /r/LocalLlama subreddit. It focuses on the performance and issues encountered when using vLLM with an RTX 3090. The performance of vLLM, including handling concurrent requests and different quantization methods, is highlighted. The section also mentions a GitHub pull request for Qwen2VL support in llama.cpp and the upcoming integration of llama.cpp's K/V cache quantization in Ollama, emphasizing the importance of model-specific optimizations for memory usage and performance.
Qwen 2.5 Coder 32B vs Claude 3.5 Sonnet: Performance and Comparison
Qwen 2.5 Coder 32B vs Claude 3.5 Sonnet: Local Performance Comparison
The comparison between Qwen 2.5 Coder 32B and Claude 3.5 Sonnet reveals differences in their handling of complex code analysis tasks. While Sonnet excels in precise solutions and project understanding, Qwen struggles with assumptions and produces unusable code due to inefficient knowledge handling through RAG. Users recommend limiting the context of Qwen to enhance performance, stressing its cost-effectiveness and data privacy advantages. The discussion emphasizes the importance of correct setups and parameter tuning to maximize Qwen's potential.
Evaluating best coding assistant model running locally on an RTX 4090 from llama3.1 70B, llama3.1 8b, qwen2.5-coder:32b
An evaluation on an RTX 4090 compares llama3.1:70b, llama3.1:8b, and qwen2.5-coder:32b models. Despite llama3.1:70b's detailed analysis, llama3.1:8b emerges as more efficient. However, qwen2.5-coder:32b surpasses both in bug detection, implementation quality, and practicality, demonstrating superior performance fitting well within the RTX 4090 capabilities.
Discord Discussions on Innovative AI Technologies
The Discord channels are buzzing with the latest advancements in AI technologies. From the launch of new models like Pixtral Large and Qwen 2.5 Turbo to the introduction of frameworks like AnyModal and advancements in stable diffusion models, developers and enthusiasts are actively engaged in exploring cutting-edge AI solutions. Discussions cover a wide range of topics including multimodal capabilities, reinforcement learning benchmarks, GPU optimizations, and model integrations. These conversations not only highlight the progress in AI research but also address challenges and optimizations to enhance the efficiency and effectiveness of AI systems.
Structured Citations and Perplexity Models
The Perplexity models beta has launched a new feature supporting a 'citations' attribute, enhancing completion responses with associated links to reliable sources such as BBC News and CBS News. The structured citation format includes a citations array for better reference, improving user experience by providing easier access to the sources of information presented in chat completions.
Off-Topic Discussions
Jordan Peterson's 'Precisely' Moment:
- A GIF of Jordan Peterson confidently stating 'precisely' sparked discussion, showcasing his memorable expression.
- The humorous appeal of the GIF was noted, especially in the context provided.
YouTube Video Shared:
- A link to a YouTube video was shared without specific details, prompting surprised reactions from viewers.
- The reaction led to light-hearted comments and expressions of disbelief.
Unique Aussie Character:
- A remark about 'Aussies are built different' emerged, evoking humor regarding Australian culture or traits.
- The comment resonated with perceptions of Australians and generated laughter among participants.
Random Link Humor:
- A humorous remark about 'PERPLEXITY FREE CLICK LINK CLICK LINK' reflected an eager call to action from a random individual, drawing amusement from many.
- Similar behavior noted in Ollama Discord added to the light-hearted conversation.
Starting a Part-Time Job:
- An announcement of starting a part-time job led to a member expressing their transition from 'broke to less broke' with playful camaraderie warnings.
- The conversation sparked light-hearted exchanges about caution in handling tasks.
Perplexity AI Announcements and Messages
Perplexity AI Announcements
- Canadian Students Get a Free Month of Pro: Offers Canadian students a free month of Pro with their student email for a limited time. Encourages sharing the offer with friends.
- Perplexity Shopping Transforms Online Shopping: Introduces the Perplexity Shopping platform for convenient product research and purchases, featuring one-click checkout and free shipping on selected products.
- 'Buy with Pro' Revolutionizes Transactions: Allows US Perplexity Pro users to transact natively on the app, enhancing the shopping experience for electronics and home products.
Messages on General Dissatisfaction
- Dissatisfaction with Perplexity Pro Subscription: Users express frustration over changes, particularly the removal of the Opus model without notice, leading to inquiries about refunds.
- Introduction of Shopping Feature Raises Concerns: Some users feel the new shopping feature emphasizes monetization over user experience, affecting the core functionality of the AI assistant.
- Changes to Context Memory Sizes: Users report decreased context memory size dissatisfaction affecting model effectiveness for longer interactions.
- Access and Model Availability Based on Region: Users outside the U.S. express dissatisfaction with limited models, calling for transparency in model accessibility.
- Calls for Improvement and Transparency: Users urge Perplexity to focus on transparency and compliance with consumer laws regarding subscription offerings.
HuggingFace: Questions and Tips
Configuring Aider with OpenRouter:
To configure Aider to use an OpenRouter model, settings must be made on the OpenRouter side, as it currently does not support per-model settings on the client side. Members discussed using extra parameters and config files to specify different behavior but expressed limitations with the current setup.
Handling Token Limits in Aider:
Several users discussed issues with hitting token limits, particularly when using OpenAI compatible APIs with local models like Qwen. Some suggested creating a .aider.model.metadata.json file to manually set token limits, although users reported varying success with that approach.
Using Aider with Local Models:
Users have successfully run Aider with local models via OpenAI compatible APIs, experiencing some notifications about token limits that haven't affected output. Discussion pointed to certain configurations required to set up local environments properly, noting the necessity to check metadata files.
Extra Parameters for Litellm:
It was confirmed that additional parameters can be added via extra_params in Litellm, allowing users to inject headers for API calls. There was no environment variable interpolation for these headers, requiring users to set them manually.
Benchmark Run Skipped Tests:
A user inquired about checking older benchmark runs for any tests that may have been skipped due to connection timeouts. Responses indicated that there does not seem to be a method available for inspecting these runs for specific skips.
Exploring Prompt Engineering and AI Discussions
This section delves into discussions on OpenAI's GPT model, focusing on prompt engineering challenges and interactions. Members highlighted the complexity of crafting effective prompts and the prevalence of negative prompting. They explored the feasibility of LLMs learning from each other and the potential of introspective prompts. The effectiveness of chain of thought prompting was emphasized to improve response quality. Additionally, there was a discussion on user criticisms of AI outputs, noting the different standards applied. The section also touches upon the impact of narrative reasoning on AI and the potential for discovering new techniques to influence model responses.
Understanding the Advancements in LM Studio and GPU Usage
Adjusting prompt strings impacts visuals allowing creative customizations. Discussions highlighted concerns about Roop Unleashed's processing times for face-swap videos and preference for SDXL Lightning over older models for better image quality. Advancements in newer models, GPU comparisons, and challenges with mixed setups were appreciated. Additionally, discussions on LM Studio server accessibility, AI video upscaling tools, and port forwarding queries were noted. Users emphasized the efficiency and compatibility of Nvidia GPUs for AI tasks. The section also covered topics like power management, GPU memory compatibility, and the challenges of mixed GPU setups. Conversations in Nous Research AI delved into frameworks like Ollama, AnyModal, and updates on decentralized training runs. The community explored topics like LLM integration for video creation, function calling in LLMs, and comparisons of modern LLMs with GPT-3. Lastly, papers discussed fine-tuning LLMs for domain adaptation, VLA models in robotic tasks, and enhancing reasoning capabilities in LLMs. LLM2CLIP's utilization for improved visual representation was also outlined.
Interconnects - AI General Chat
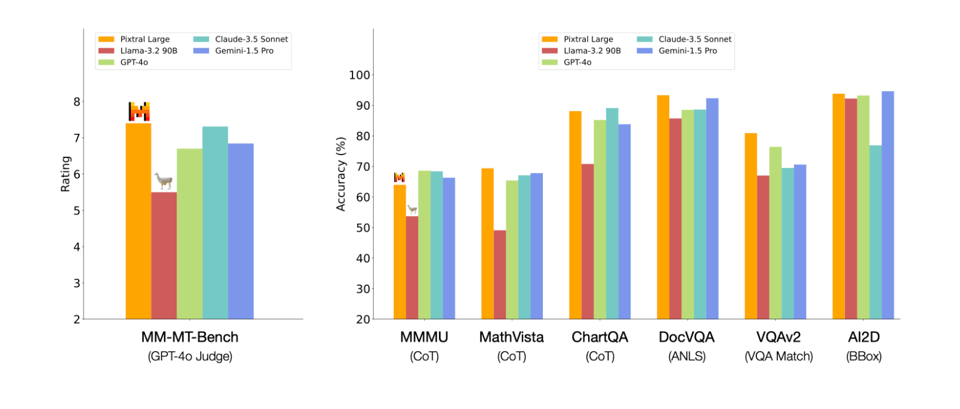
Pixtral Large debuts as new multimodal model: Mistral announced the release of Pixtral Large, a frontier-class 124B multimodal model capable of understanding documents and images while maintaining text performance, available in their API and on Hugging Face.
- It boasts a 128K context window and can process a minimum of 30 high-resolution images, showcasing advancements in multimodal AI.
- Mistral updates Le Chat with new features: Mistral's Le Chat now includes features like web search, image generation, and PDF upload, aiming to enhance user interaction with generative AI tools.
- The platform is now free to use and supports various use cases, from coding assistants to creative partnerships, pushing the boundaries of AI interfaces.
- Qwen 2.5 Turbo introduces extended context support: Qwen 2.5 Turbo now supports context lengths of up to 1 million tokens, allowing for comprehensive text processing equivalent to ten novels.
- This model achieves 100% accuracy on the Passkey Retrieval task, significantly enhancing long-context capabilities for developers.
- Mixed reviews about Lindy usage: A user expressed their struggle to find substantial use cases for Lindy, questioning its advantages over other automation tools like Zapier.
- The feedback reflects a broader hesitation within the community about its practicality and effectiveness in current workflows.
- OpenAI adds streaming feature for o1 models: OpenAI has made streaming available for the o1-preview and o1-mini models, expanding access across all paid usage tiers.
- This enhancement allows developers to leverage more dynamic interactions within the OpenAI platform, improving the user experience.
GPU Mode - Triton Puzzles
jongjyh thanked for something in this channel.
Mojo Benchmarking and Issues
A member raised concerns regarding benchmarking with random function arguments in Mojo and suggested pre-generating data to avoid overhead. Another user faced issues with Pstate drivers on WSL2, hinting at potential Mojo runtime challenges. Additionally, a crash related to Dict usage in Mojo was reported, emphasizing limitations beyond a SIMD size of 8. There were also discussions about struct implementation issues with AstNode and handling CPU frequency errors. Links referenced Variant types, Dict issues on GitHub, and more.
Cohere Developer Office Hours and Toolkits
Join the Cohere Developer Office Hours session focused on handling long text and real-world use cases, featuring insights from Maxime Voisin and tips on implementing memory in RAG systems. Learn about summarization techniques for compressing long text and discuss specific use cases like File Upload and SQL Query Generation. The session encourages active participation and sharing of challenges. Additionally, the Toolkit v1.1.3 release introduces new features like support for ICS files and tools toggling for custom Assistants. Bug fixes and maintenance updates aim to enhance the Toolkit's usability. Future features include a Hot keys binding button, Gmail + SSO integration, and improvements for Azure deployment with Docker compose. Development experience enhancements prioritize build processes, running, debugging, and user feedback for Toolkit improvements.
Updates and Improvements in Various Areas
Key points for the release include progress in blocks, lazy buffers, and performance enhancements with Qualcomm scheduling. There was a discussion on convenience methods for Tinygrad, where integrating methods like scatter_add_ and xavier_uniform from frameworks like Torch and TensorFlow was suggested. Clarification on the Int64 indexing bounty was addressed, with concerns over its functionality leading to talks on enhancing documentation and clarity. Members discussed improvements in Graph and Buffer Management within Tinygrad, aiming to refine the Big Graph and LazyBuffer concepts, ultimately planning to delete the LazyBuffer to streamline processing and track UOp Buffers for better performance and functionality in the project.
Messaging Interaction
rotem2733 initiated a conversation with the message 'Hello?' via the jamba channel.
FAQ
Q: What are the key performance considerations when using vLLM with an RTX 3090?
A: The performance of vLLM on an RTX 3090 is highlighted in terms of handling concurrent requests, different quantization methods, and model-specific optimizations for memory usage and performance.
Q: How does Qwen 2.5 Coder 32B compare to Claude 3.5 Sonnet in handling complex code analysis tasks?
A: Qwen 2.5 Coder 32B and Claude 3.5 Sonnet show differences in their approach towards complex code analysis tasks, where Sonnet excels in precise solutions and project understanding while Qwen struggles with assumptions and may produce unusable code due to inefficient knowledge handling.
Q: What models were evaluated on an RTX 4090, and which model demonstrated superior performance?
A: llama3.1:70b, llama3.1:8b, and qwen2.5-coder:32b models were compared on an RTX 4090, with qwen2.5-coder:32b surpassing both llama3.1 models in bug detection, implementation quality, and practicality, showcasing superior performance within the capabilities of the RTX 4090.
Q: What advancements and discussions have been taking place in the AI communities?
A: Discussions in AI communities cover topics like new model launches such as Pixtral Large and Qwen 2.5 Turbo, advancements in frameworks like AnyModal, stable diffusion models, multimodal capabilities, reinforcement learning benchmarks, GPU optimizations, and model integrations, reflecting the active engagement in exploring cutting-edge AI solutions.
Q: What are some of the notable announcements and features in the Perplexity AI platform?
A: Perplexity AI has introduced features like 'Canadian Students Get a Free Month of Pro', 'Perplexity Shopping' platform for convenient product research and purchases, and 'Buy with Pro' for native transactions on the app. However, users have expressed dissatisfaction over changes in subscriptions, the introduction of the shopping feature, context memory size adjustments, and regional model availability.
Q: How can Aider be configured with local models such as Qwen for handling token limits?
A: Aider can be configured with local models by setting extra parameters and modifying config files to manage token limits while discussing challenges like hitting token limits and the need to check metadata files for proper setup.
Q: What are the discussions surrounding prompt engineering challenges and interactions with OpenAI's GPT model?
A: Discussions focus on prompt engineering challenges, negative prompting, feasibility of LLMs learning from each other, introspective prompts, chain of thought prompting, user criticisms of AI outputs, impact of narrative reasoning on AI, and techniques to influence model responses.
Q: What new models and features have been introduced in the ongoing AI advancements?
A: Recent advancements include the release of Pixtral Large, Le Chat updates from Mistral, extended context support in Qwen 2.5 Turbo, mixed reviews about Lindy, and the streaming feature for o1 models by OpenAI, showcasing diverse developments and community feedback.
Q: What are some challenges and updates discussed in the development of frameworks like Tinygrad?
A: Challenges in Tinygrad development involve conveniences methods integration, Int64 indexing considerations, improvements in Graph and Buffer Management, and performance enhancements with Qualcomm scheduling, reflecting ongoing enhancements and discussions within the framework.
Get your own AI Agent Today
Thousands of businesses worldwide are using Chaindesk Generative
AI platform.
Don't get left behind - start building your
own custom AI chatbot now!