[AINews] Qwen with Questions: 32B open weights reasoning model nears o1 in GPQA/AIME/Math500 • ButtondownTwitterTwitter
Chapters
AI Twitter and Reddit Recaps
Qwen2.5-Coder-32B-Instruct-AWQ Benchmarking
Discord Community Discussions on Various AI Topics
LOW PRECISION AND LLM CODER: AI ENGINEERS' PERFORMANCE ENHANCEMENT
Recent Developments in Extensibility and Model Transfer
Interconnects: Nathan Lambert Reads
Deeper Insights into AI Startups and Models
Cohere Projects
GPU Mode ThunderKittens
Axolotl AI, Gorilla LLM, LAION, and more Updates
AI Twitter and Reddit Recaps
AI Twitter Recap
-
Hugging Face and Model Deployments: Hugging Face now supports deploying llama.cpp-powered instances on CPU servers. Also, Marker v1 was released, a faster and more accurate tool for AI model deployment. There were discussions about Agentic RAG developments focusing on robust RAG systems utilizing external tools.
-
Open Source AI Momentum: The popularity of models like Flux on Hugging Face was highlighted, indicating a shift towards multi-modal models gaining usage. There was a notable increase in the usage of image, video, audio, and biology models in enterprise settings. SmolLM announced an internship opportunity for training LLMs.
-
NVIDIA and CUDA Advancements: Discussions were held on CUDA graphs, PyTorch enhancements, torch.distributed capabilities in relation to NVIDIA GB200 NVL72, and optimizing DataParallel in PyTorch.
-
Impact of VC Practices and AI Industry Insights: Views were shared on Venture Capital practices, managing entry-level programmers, and the role of Stripe in improving business data quality.
-
Multimodal Model Development: ShowUI, a vision-language-action model, was discussed along with QwenVL-Flux, enhancing multimodal AI applications.
-
Memes and Humor: Humorous takes on AI development, Neuralink, and AI enthusiast culture were shared. A fictional scenario exploring AI in toy reimaginations was also discussed.
AI Reddit Recap
/r/LocalLlama Recap
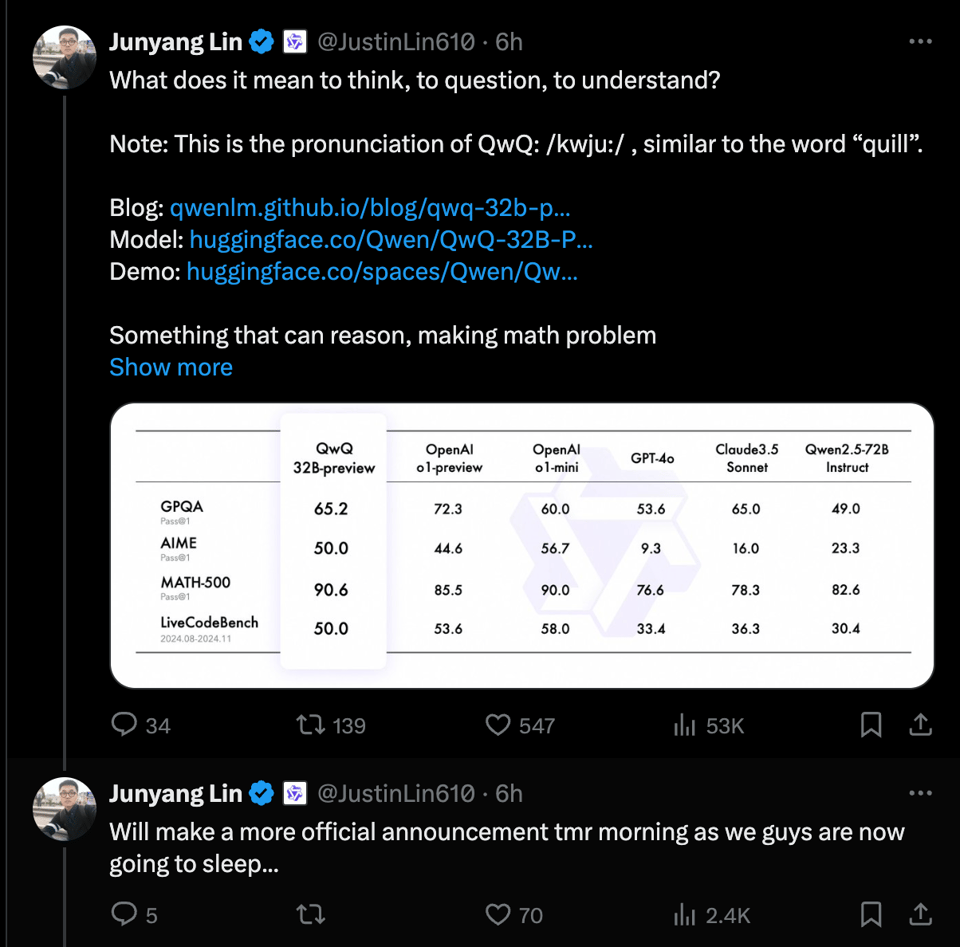
- QwQ-32B: Qwen's New Reasoning Model Matches O1-Preview: Qwen announced the preview release of their 32B language model called QwQ. Initial testing suggests QwQ-32B performs similarly to OpenAI's O1 preview, with users noting its verbose reasoning process. This model uses quantized versions for different VRAM sizes and requires a specific system prompt for optimal performance. Users reported strong performance on complex reasoning questions but noted limitations and variable performance compared to other models.
Qwen2.5-Coder-32B-Instruct-AWQ Benchmarking
Qwen2.5-Coder-32B-Instruct-AWQ model was benchmarked using AWQ quantization on 2x3090 GPUs, achieving a peak pass@2 score of 74.6% with specific configurations. Users showed interest in VRAM usage and temperature=0 testing. The AWQ_marlin quantized model is available on Huggingface for runtime use. Additionally, there were suggestions to test min_p sampling with recommended parameters and discussions on its benefits in a Hugging Face discussion.
Discord Community Discussions on Various AI Topics
The discussions on OpenAI Discord highlighted conversations around Sora Video Generator leak, ChatGPT's Image Analysis, empirical prompting research, AI Phone Agents, and Model Testing Frameworks. Nous Research AI Discord focused on MH-MoE's efficiency, Star Attention mechanism, DALL-E's Variational Bound controversy, Qwen reasoning model, and OLMo-0424's performance. Eleuther Discord talked about RWKV-7 potential for soft AGI, Mamba 2 architecture's efficiency, SSMs and graph curvature relation, and RunPod server configurations for OpenAI endpoint. OpenRouter Discord shared updates on Gemini Flash 1.5 capacity boost, Provider Routing Optimization, Grok Vision Beta launch, EVA Qwen2.5 pricing changes, and Jamba 1.5 model issues. Interconnects Discord engaged in discussions about QwQ-32B-Preview, Olmo vs Llama models, Low-bit Quantization benefits, Deepseek's R1 model, Bsky Dataset controversy, and its impact on social media research. Perplexity AI Discord sections covered the deprecation of Perplexity Engine, Image Generation in Perplexity Pro, enhanced model selections, financial data sources, and Reddit citation support challenges. Aider Discord talked about Sonnet's PDF support, QwQ model's performance issues, Whisper API for privacy, and Axolotl vs Unsloth frameworks comparison. Unsloth AI Discord discussed dataset quality over framework choice, RTX 3090 pricing variability, GPU hosting solutions, finetuning local models with multi-GPU, and understanding order of operations in equations. Stability.ai Discord focused on wildcard definitions debate, image generation workflow challenges, ControlNet performance, creating high-quality images, and Stable Diffusion plugin issues. Notebook LM Discord shared experiences with satirical testing, AI's voice and video showcase, Gemini model evaluations, functionality concerns, and podcast duration challenges. Cohere Discord covered API integration issues with LiteLLM, citation support enhancements, and a profile of a Full Stack AI Engineer. Latent Space Discord highlighted PlayAI's funding news, OLMo 2 model's performance, SmolVLM for on-device inference, Deepseek's reasoning model, Enterprise Generative AI spending trends, and challenges in defining implementation strategies. GPU MODE Discord discussed LoLCATs Linear LLMs, ThunderKittens' FP8 launch, FLOPS counting tools, and cublaslt for accelerating large matrices.
LOW PRECISION AND LLM CODER: AI ENGINEERS' PERFORMANCE ENHANCEMENT
The optimization for low precision in large matrices showcases impressive speed in matrix operations, particularly beneficial for AI engineers seeking to boost performance in extensive matrix computations. The LLM Coder project aims to enhance Claude's understanding of libraries by providing main APIs in prompts and integrating them into VS Code. This initiative seeks to deliver more accurate coding suggestions, inviting developers to express interest and contribute to its development.
Recent Developments in Extensibility and Model Transfer
The recent release of MAX version 24.3 emphasizes its extensibility, allowing users to create custom models using the MAX Graph APIs. The Graph API supports high-performance symbolic computation graphs in Mojo, positioning MAX beyond just a model format. Unlike ONNX which focuses on model transfer, MAX prioritizes performance, indicating its goal to optimize real-time model inference. Users have expressed frustrations and appreciation for the Cursor Agent, highlighted the latest version rollout features, and discussed implementing custom tools like the Model Context Protocol (MCP) within Cursor for enhanced user experiences. OpenAI discussions covered the leak of Sora Video Generator, testing ChatGPT's image analysis capabilities, community engagement, translation challenges, and the usage of AI in content creation. Users inquired about accessing ChatGPT for free, discussed ChatGPT's reliability and validity, and explored best practices for GPT file interactions. In other sections, conversations revolved around prompting research, model testing frameworks, AI phone agents, and RAG for file referencing in the context of OpenAI's work. Additionally, advancements in OLMo models, GPU rental experiences, nous Hermes model comparisons, and discussions on Qwen reasoning model were outlined, emphasizing advancements in AI technologies. The section also delved into financial economics, Bayesian statistics, and algorithmic trading experiences related to AI research at Nous Research.
Interconnects: Nathan Lambert Reads
- Low-bit quantization benefits undertrained LLMs: Research indicates that low-bit quantization favors undertrained Large Language Models (LLMs) due to their susceptibility to overfitting with full-precision weights. This approach could lead to efficient model inference and reduced computational requirements.
- Deepseek's AI advancements: Deepseek's advancements in Artificial Intelligence, particularly in the realm of information retrieval and search optimization, have gained attention within the community for their innovative approaches to enhancing search algorithms and user experience. These developments showcase the potential for AI to revolutionize information discovery processes.
- CEO Liang Wenfeng's background: Insights into CEO Liang Wenfeng's background shed light on the leadership within Deepseek and provide context to the company's strategic direction and priorities. Understanding the experience and expertise of the CEO can offer valuable perspectives on the organization's trajectory and goals.
- High-Flyer's role in Deepseek: The discussion around High-Flyer's involvement in Deepseek suggests a collaborative effort or a partnership that contributes to the company's growth and success. High-Flyer's specific contributions and areas of influence within Deepseek could indicate strategic alignments or shared objectives between the entities.
- Compute resources in AI development: Explorations into the utilization of compute resources in AI development highlight the importance of efficient resource management and allocation for training and deploying advanced AI models. Understanding the infrastructure and computational demands of AI projects is crucial for optimizing performance and scalability.
Deeper Insights into AI Startups and Models
This section delves into the undertrained large language models and the impact of quantization-induced degradation on larger models. It also highlights the success of Deepseek in beating OpenAI on reasoning benchmarks and provides insights into the impressive background of CEO Liang Wenfeng. The section also discusses Deepseek's focus on foundational technology and funding from High-Flyer, showcasing its competitive advantage. Additionally, it mentions the extensive compute clusters at High-Flyer, positioning Deepseek competitively in the AI landscape. Lastly, it sheds light on the advancements in AI technology and the scaling capabilities of Deepseek powered by High-Flyer's resources.
Cohere Projects
A member shared their expertise as a Full Stack AI Engineer with over 6 years of experience in designing and deploying scalable web applications. They possess skills in diverse technologies like React, Angular, Django, FastAPI, Docker, Kubernetes, and CI/CD pipelines across cloud platforms like AWS, GCP, and Azure. Additionally, they specialize in AI development using TensorFlow and PyTorch for NLP, computer vision, and recommendation systems, along with advanced NLP techniques using LLMs and libraries like Hugging Face Transformers and spaCy. The member also works with knowledge graphs and vector databases for AI agents, ensuring secure, scalable solutions in microservices and serverless architectures. They showcase their projects on GitHub and welcome discussions on AI, software engineering, and tech challenges.
GPU Mode ThunderKittens
Today marks the launch of FP8 support and fp8 kernels in ThunderKittens, addressing community requests for quantized data types and achieving 1500 TFLOPS in just 95 lines of code. Kernel implementation details have been shared to simplify kernel writing and facilitate research on new architectures. The team behind the project includes notable members like Benjamin Spector and Chris Ré, contributing to its development.
Axolotl AI, Gorilla LLM, LAION, and more Updates
Axolotl AI
- Community excitement over SmolLM2-1.7B launch and Transformers.js v3 release.
- Frontend LLM tasks integration showcased advancements in app development.
- Inquiries about Qwen 2.5 model fine tuning and model configuration settings.
MLOps @Chipro
- Feature Store webinar details and Multi-Agent Framework Bootcamp announcement.
MLOps @Chipro General-ML
- Discussion on LLMOps and the impact of large language models in technology.
LAION General
- User struggles and proposed strategies for efficient audio captioning using Whisper.
Gorilla LLM (Berkeley Function Calling)
- Updates on Llama 3.2, multi turn categories impact, significant leaderboard score fluctuations, and upcoming generation results release.
LLM Agents (Berkeley MOOC)
- Troubleshooting missing quiz score emails and confirmation email issues.
Mozilla AI Announcements
- Hidden States Unconference, RAG app creation workshop, ESM-1 protein model discussion, San Francisco Demo Night, and Data Bias Seminar details.
AI21 Labs (Jamba) General-Chat
- Challenges faced in using the Jamba 1.5 Mini Model with OpenRouter and function calling issues.
FAQ
Q: What is the significance of Hugging Face supporting deploying llama.cpp-powered instances on CPU servers?
A: Hugging Face's support for deploying llama.cpp-powered instances on CPU servers is significant as it allows for efficient deployment of AI models on hardware that may not have GPU capabilities, expanding accessibility and utilization of AI models in various environments.
Q: What advancements were discussed regarding NVIDIA and CUDA in relation to AI development?
A: Discussions on NVIDIA and CUDA advancements included topics such as CUDA graphs, PyTorch enhancements, torch.distributed capabilities, and optimizing DataParallel in PyTorch, showcasing the continuous improvement and optimization of tools and frameworks for AI development.
Q: How does low-bit quantization benefit undertrained Large Language Models (LLMs)?
A: Research suggests that low-bit quantization benefits undertrained LLMs by favoring their susceptibility to overfitting with full-precision weights, leading to efficient model inference and reduced computational requirements, which can enhance the performance of such models.
Q: What are some of the key advancements in AI technology discussed in the Reddit recap section?
A: Advancements highlighted in the AI Reddit recap section included Qwen's new reasoning model QwQ-32B, AI advancements by Deepseek in information retrieval and search optimization, insights into CEO Liang Wenfeng's background, and discussions on the role of compute resources in AI development, providing a broad view of recent developments in the field.
Q: Why is understanding the CEO's background valuable for gaining insights into a company's strategic direction?
A: Insights into a CEO's background, such as CEO Liang Wenfeng's, are valuable as they provide context to the leadership within a company, offering perspectives on strategic direction and priorities that can impact the organization's trajectory and goals.
Get your own AI Agent Today
Thousands of businesses worldwide are using Chaindesk Generative
AI platform.
Don't get left behind - start building your
own custom AI chatbot now!